Menu


模型训练从千亿到万亿,数据规模也不断的膨胀,算力需求也随之呈指数级增长,致使千卡集群也在向万卡集群进行演进,如何有效提升训练效率、降低算力卡故障率、增强数据协同能力,已成为智算中心亟需解决的关键问题。
绿算技术GP5000/GP6000系列存储产品基于RoCEv2协议的RDMA网络架构,支持GPUDirect Storage技术,实现端到端访问时延(≤4μs)(基于MLPerf存储基准测试),并将Checkpoint时间控制在分钟级别,有效减少算力卡故障导致的数据损失和时间浪费。该系列产品的单节点带宽可达72GB/s(GP5000)或144GB/s(GP6000的144GB/s满足H100 GPU全速数据供给),确保算力数据的高效读写,实现卡间数据的高效协同,打造了一套完整的AI训推流程。通过提升规模级算力应用的效率,为AI计算的高效运营提供了全面的解决方案。
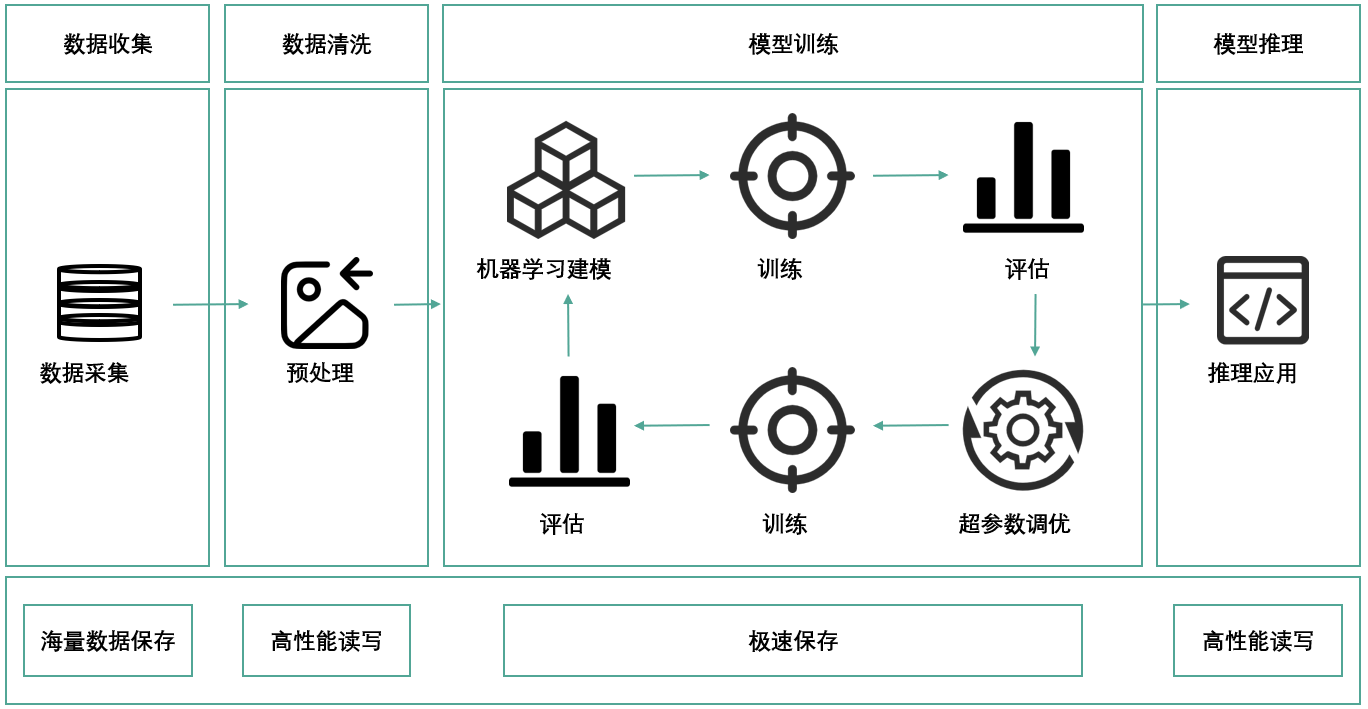

海量数据保存:采用客户现有的存储产品,进行全量数据收集; 高性能读写:通过传统分布式存储与绿算GP5000/GP6000,一方面提升存储容量,另一方面显著提升传统分布式存储的性能,实现成本效益的最优平衡; 极速保存:采用绿算GP5000/GP6000,以高带宽实现算力数据的高效读写和数据协同操作。
