Menu

近年来随着云计算、5G、元宇宙等新技术的发展,企业对数据资产越来越看重,尤其数据的实时性价值;为满足数据响应速度的需求,自然要求存储产品在单位时间内尽可能提高10、降低延迟;传统基于iSCSI、FCFCOE等协议的存储设备已不能满足新兴应用日益高涨的需求。广东省绿算技术有限公司(以下简称“绿算技术”)经过多年的研发,推出了基于NVMe overFabrics协议(简称NVMe-oF)的ForinnBase GroundPool全闪存储,系统具有低延时、高带宽、高吞吐等特点。
绿算技术提供的全闪存储解决方案,可广泛应用于大型在线交易系统、大数据采集与分析、4K/8K视频编辑、5G数据应用、AI人工智能和自动驾驶系统等业务场景,满足金融、互联网、科研、广电、军工和电信等行业的高速数据处理需求。

LightBoat2300系列基于超规模+架构,集成VU23P芯片,提供2252K逻辑单元、1320 DSP切片及99 Mb超内存,支持4.1TOPS算力。板卡配备双100G以太网(QSFP28)、PCle Gen 4x8接口及4GBDDR4内存,支持高速数据传输与复杂计算。34路GTY收发器(32.75 Gb/s)和4路GTM通道(58 Gb/s)保障低延迟通信,兼容工业级环境。75 W电脑供电+120W外部供电设计,兼顾能效与性能。适用于数据中心网络加速、人工智能推理及工业边缘计算,以高吞吐、灵活扩展和低功耗为核心优势。
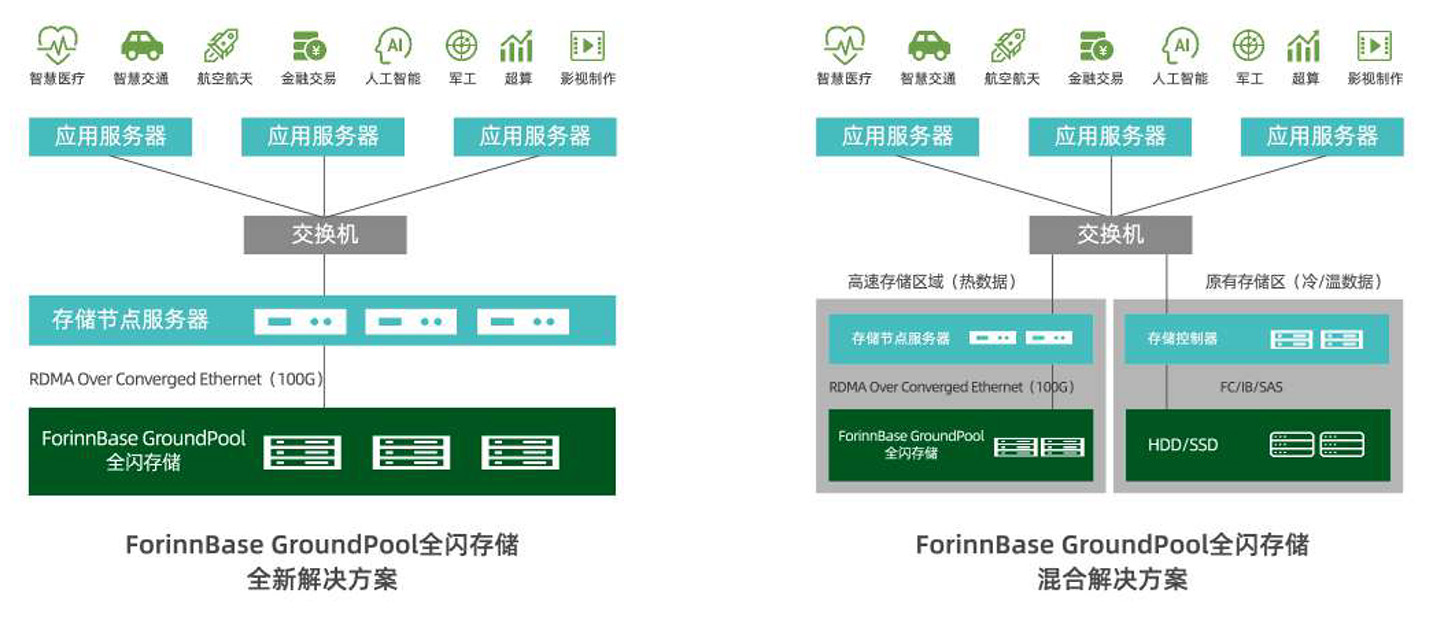
ForinnBase GroundPool全闪存储基于ASIC方案设计,系统利用硬件级的NVMe-0F交换系统及100GbE的以太网交换矩阵,通过NVMe-0F 网络无损访问SSD,充分释放了NVMeU.25SD的极限性能,系统采用标准以太网传输,极大简化部署及维护,方便数据中心高性能存储系统的部署。
采用双主控板双活冗余设计,当一块主控板发生故障时,另一块主控板自动接管业务,可以保障业务的持续性。
采用模块化设计,当某个模块产生故障时,方便快速替换减少故障时间,提高设备的可用性。
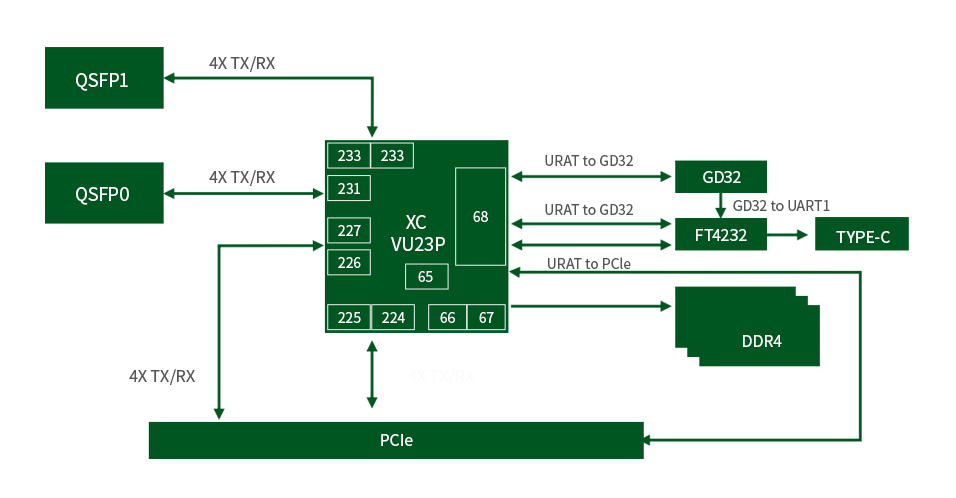

基于16nm UltraScale+工艺与3D堆叠技术,集成58个高速收发器,支持200G SmartNIC加速,实现超高逻辑密度与能效平衡,显著降低CPU负载。

适配5G基站、AI推理、金融高频交易等多元场景,通过硬件级优化满足智能网络与数据中心的低延迟、高吞吐需求。

支持Vitis开发平台与Arm处理器异构协同,提供从硬件部署到算法优化的全流程加速方案,兼容边缘计算与云协议演进。

通过智能网卡卸载与能效比提升技术,降低数据中心总体拥有成本(TCO),助力智能基础设施高效构建。
其主要场景是满足超高性能的读写需求,主要应用方向如下:
遥感行业卫星数据的快速传输存储卫星每天与地面通信的时间是固定,在每天单位时间内,存储写入的速度越快,单位时间内卫星能够传输的数据越多,现行的解决方式构建大量的分布式存储(多个机房的存储)来予以实现,通过全闪存储作为前端存储缓存,结合后端传统存储,能够大大节省资源的开销(电力资源、碳排放、设备维护成本等);同时,高性能存储也可采用分布式部署方式,能够大大提升整体的业务能力。
新零售业务并发交易新零售业务在每年促销时段存在超并发的交易行为,其对数据库中数据的查询、改写普遍采用并行实时计 算的方法,因此,存储的高性能需求强烈。
新零售业务超并发订单更多是计数,可通过缓存技术将产生的订单缓存后,再通过任务排队逐步写入到数据库中;同时,电商业务只记录订单,并不会实时同步查询库存数量,因此,对于数据库(数据库数据全部存储于存储中)的压力可以通过多集群、多队列、多缓存技术解决。
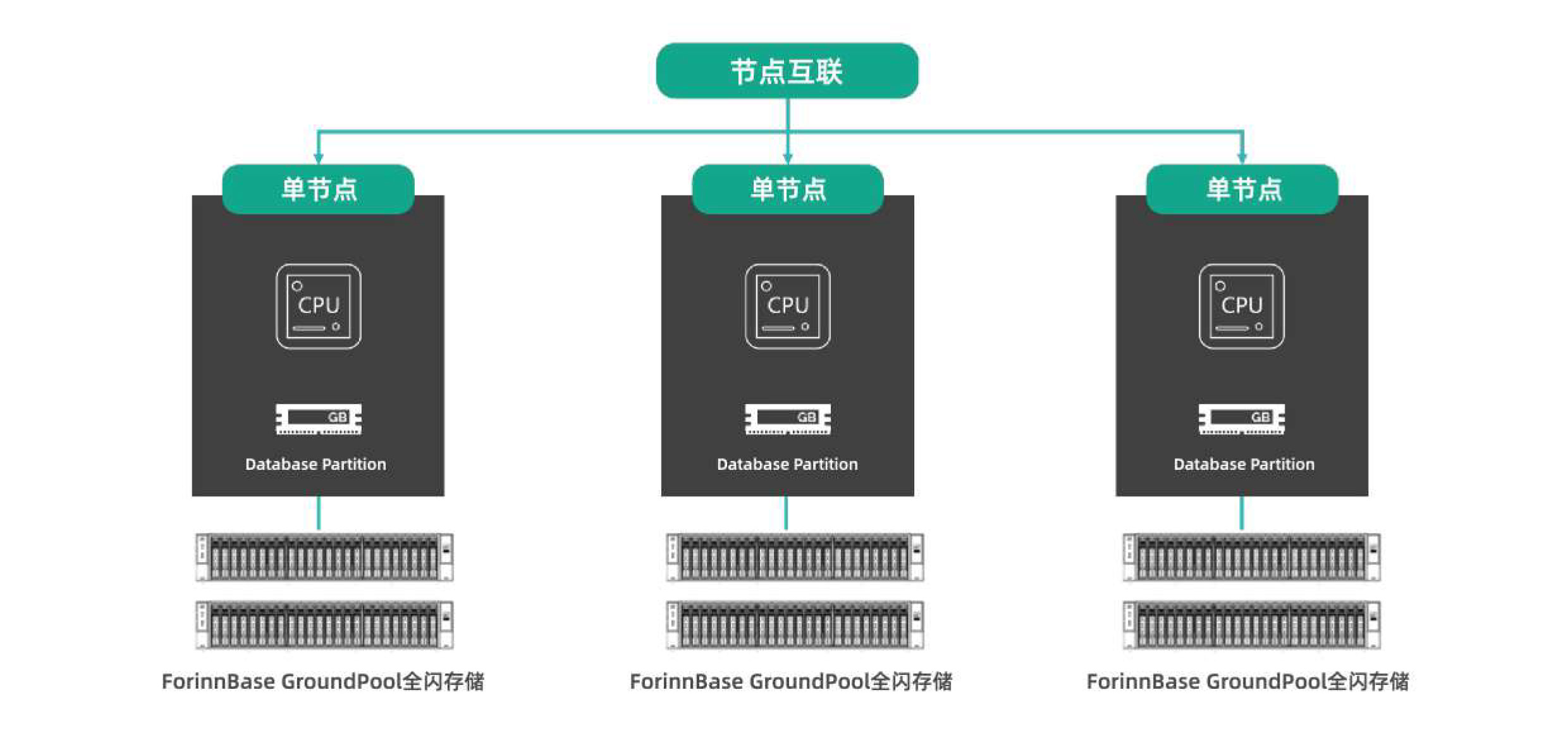
MPP大规模并行运算MPP并行运算由于其结构的不同,各节点间只能访问自己的资源,即形成单一资源利用,而MPP一般负责大型的数据运算,因此对于复杂的数学难题,其每个节点的计算速度决定了最终结果的计算速度。所以,提升单节点性能,对于MPP效率有足够大的提升(国家超算中心)。 而已知的单套节点(所有单节点,包括个人计算机),其影响整体速度的并不在计算资源部分,而是存储资源部分,因此,全闪存储能有效提升计算效率。
IT业务中,根据日常运维的经验,80%以上的问题都是由数据库引起的,且整体业务访问耗时最多的环节往往发生在数据库层面,而数据库中的数据基本都在存储中存放,因此存储的读写效率决定了数据库的效率,根 据业务传递,最终表现在用户阶段,因此,提升存储的性能,即可以有效提升业务的整体性能。
而业务系统往往由网络设备、服务器、中间件、数据库、程序、存储等多个方面组成,在实际过程中,计算资源的性能往往是富裕的,甚至是过剩的,而存储系统,特别是机械性存储,由于机械盘片自身物理性质的原因,存在性能的物理上线,全闪存储多采用固态硬盘作为存储介质,能够有效解决机械硬盘的物理性能上线;所以,全闪存储能够有效实现业务性能的提升。
再次,全闪存储对于交易型的业务(银行、电商)提升效果显著,交易型业务普遍是高并发的业务,对于数据库的查询与写入有很高要求,而存储的I0PS直接影响数据库的并发性能,全闪存储高性能,可以有效提升交易型业务的业务处理能力。
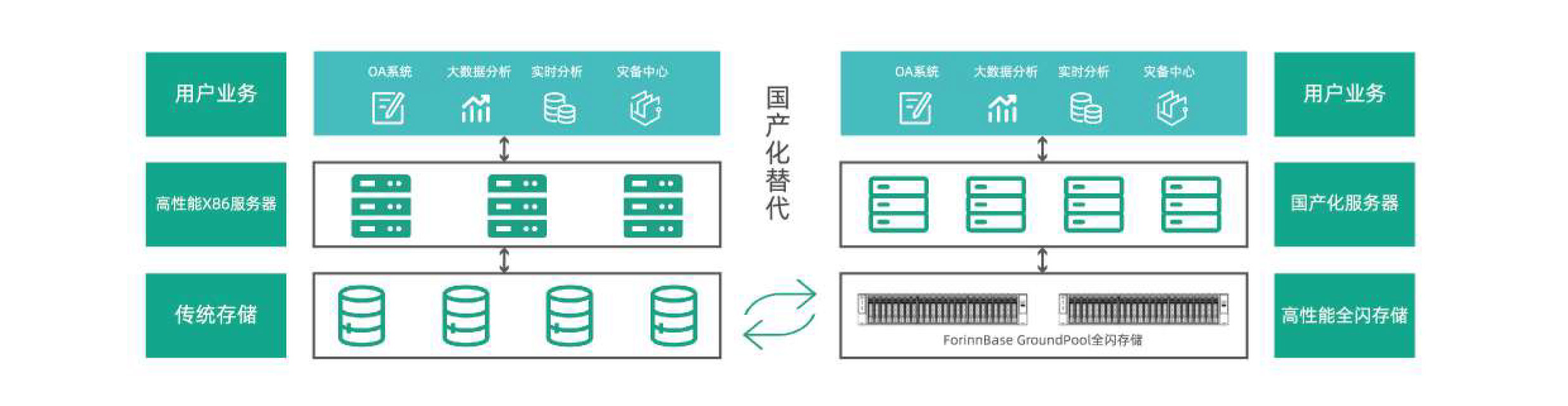
业务国产化替代过程中,需要替换大量国产化产品,如国产服务器、中间件、数据库、业务系统等产品,但国产设备在整体性能上与原有X86架构产品存在着较大差距,整体算力不足,造成一定的业务排队、积压等现象,GP高性能全闪存储产品,采用RDMA、NVMe-0F技术,使业务数据直接存储至NVMeSSD,减少CPU对数据存储的参与,将更多CPU算力用于计算任务,弥补了国产化设备算力不足的问题,同时,其具有的高吞吐、高并发、低延迟的特性,为业务国产化替代后提供快速的数据存取服务,提升业务整体性能,帮助业务快速稳定落地。
日常影响业务访问体验的问题多数出现在数据的查询与访问,而数据库一体机的三个重要的性能指标是存储设备的IOPS、时延、吞吐,而传统的机械硬盘和市面上主流的SSD固态硬盘,采用的仍是传统SATA接口或SAS接口,数据传输速度受限与SATA、SAS控制器带宽、数据的存储路径,CPU在存储上的开销也很大,想要提升数据库一体机的1/0、吞吐能力和时延只能依靠不断的增加硬件成本来实现。

数据库计算机节点与全闪存储深度集成后,数据借助零CPU开销的RDMA技术,通过计算节点PCle通道RDAM网卡直到存储节点,实现数据库高速直接的对存储单元进行读写操作,计算节点到存储节点的存储路径由传统存储7个节点减少到4个节点,时延毫秒级,压缩至20微秒以内,极大压缩了数据库一体机的访问时延,存储节点单机72GB/S吞吐带宽和1600万I0PS的超高性,能将数据库一体机的整体性能提升10倍以上,配合高密度可扩展、高可用、高可靠的特性,可以轻松承载重大行业核心应用复杂的数据库要求。
人工智能的应用场景越来越广泛,以GPT-3为代表的大模型技术已取得了前所未有的成功,ChatGPT已悄然改变众多行业形态。随着模型规模的激增,模型训练中的海量数据存取、高并发业务支持已成为影响AI发展的核心技术。在SIGMOD 2022会议中,学者专家通过实验验证众多主流模型训练效率,指出存储系统已成为AI模型训练的瓶颈,具体体现为:海量小文件I0PS压力大;带宽难以满足大数据量存取;CPU参与数据存取制约算 力发挥。
针对上述问题,绿算技术自主研发的NVMe-0F全闪存储产品ForinnBase GroundPool(简称:GP),实现了NVMe、NVMe-OF、RDMA协议的芯片(ASIC)级卸载,具备NVMe存储协议高性能、零拷贝和网络化可扩展的特性,全面支持GPU直连和网络化高性能共享功能,在提供单机高容量、高带宽、高I0PS、高扩展、低延时、低功耗等特点的数据存储功能的同时,借助GPU直连存储技术(GPU Direct storage)和存-算分离架构(Diskless Architecture),提供了为A!模型训练加速的解决方案,具备高效、灵活、经济等特点,能为AI企业IT能力升级提供了一站式服务。
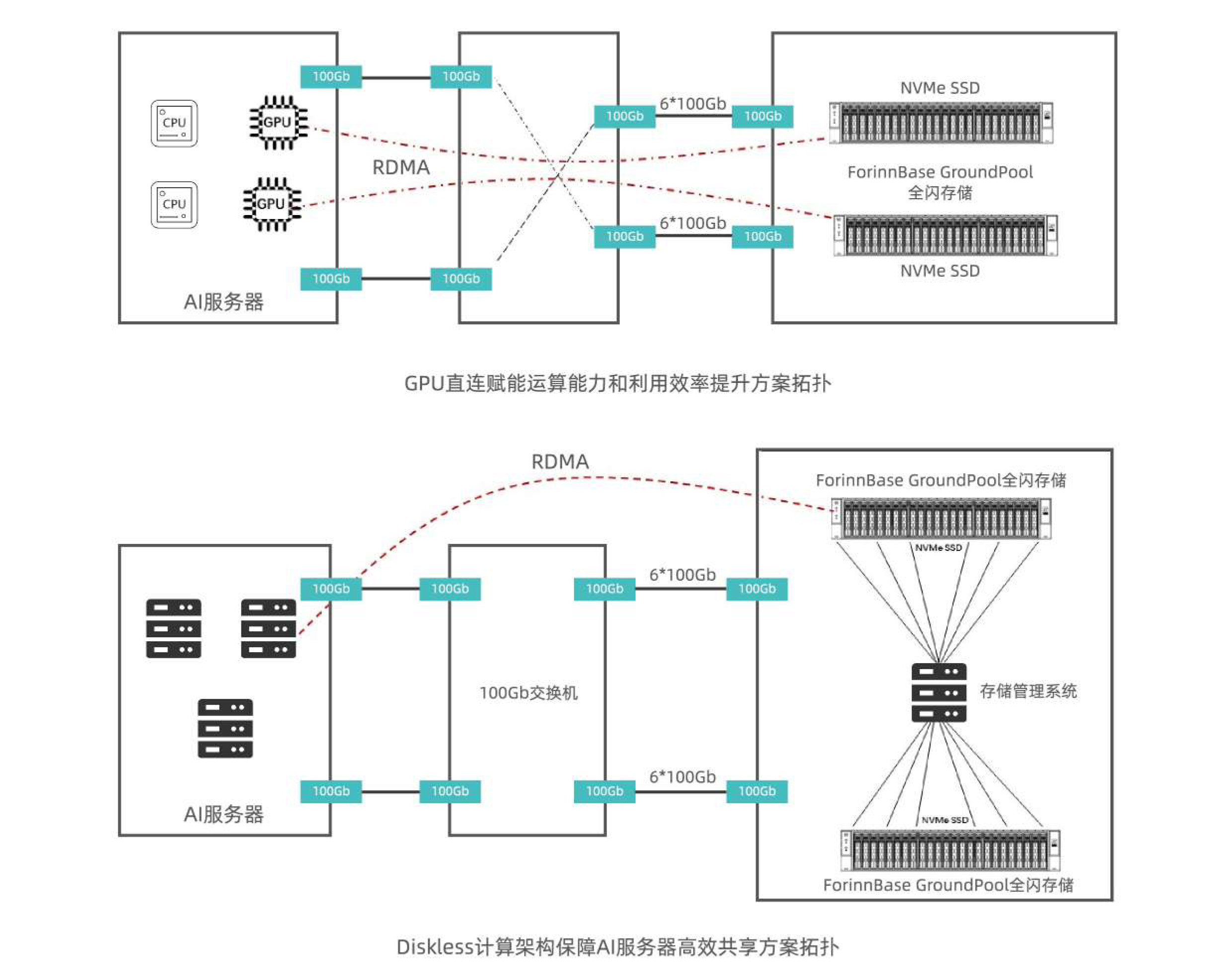
上述两种方案可有效提升AI模型训练效率,减少AI模型训练等待时间,实现数据高效安全的集中存取,满足IT设施空间和能耗限制。
在常规的数据备份、数据迁移中,传统的机械存储的整体备份时间长、备份效率低(如某银行常规备份时间为3天一次,因为数据过多,一次备份周期在1天半),而通过超性能的存储,能有效提升备份的速度,做到每天备份,有效的保障了数据的安全。
对于数据迁移能力,传统数据迁移的速度取决于存储的写入效率,超高性能的存储能有效提升数据迁移的速度,对于数据迁移能够有效提升整体迁移速度,保障业务的快速上线运行。






